Plants compete fiercely for sunlight. Many build sturdy, woody trunks to reach the sky. Some species are structurally flimsy. They grow as vines that can’t hold their own weight. Left alone, they sprawl across the dirt where their fruits rot or get devoured by tiny ground-dwelling pests.
Humans built the trellis, a vertical grid of wood or metal, to help the thing sustain itself so it can sustain us.
This post is about the kind of work that grows like a vine (code, decisions, and the reasoning of AI agents) and the structure that lets it bear fruit instead of rotting on the ground.
30-second version
Trellis is a local-first graph for things that grow but can’t hold their own weight. Trellis Studio is the workspace where you tend them. Code, agents, and the reasoning behind every change live in one substrate. Boots with
npx trellis studio.
Vines
Modern software is full of vines.
Code is one. It grows fast, branches in every direction, and would happily eat a hard drive if you let it. It doesn’t hold its own shape. What keeps it standing is the structure around it: a filesystem, a version control system, a build pipeline. Take those away and code becomes a pile of plaintext on the floor.
Project history is a vine too. Every change has a reason. Most of those reasons live in PR comments, Slack threads, or somebody’s memory. Pick any line of code in a six-month-old codebase and ask why it’s there. Most of the time, the answer is on the dirt. Eaten.
AI agents are the newest vine, and the fastest-growing. They generate code, make decisions, take actions. Almost none of that reasoning survives the session. The agent’s chat log is the only record, and it’s already not enough. RAG-over-chat-history is what happens when you try to grow a vine across the dirt and pretend it’s a garden.
Each of these vines has its own little plot of dirt: its own tool, its own format, its own way of getting eaten. The connections between them live in your head.
Trellis is a trellis
Trellis is a structural grid for the things that grow but can’t hold their own weight in a software project.
Technically: a local-first, AI-native graph engine. Code lives in the graph as entities. Every change is an op: immutable, content-addressed, causally chained. Every decision (human or AI) is a record with a reason. History is a query, not a scroll. The whole thing lives in a .trellis/ folder you can back up with cp -r.
The substrate doesn’t care whether the vine is code or notes or agent reasoning. It just holds it up.
I came to this from Filegraph, which was the same idea applied to personal knowledge: files as nodes, agent actions as ops, reasoning you could inspect. The feature people loved was the canvas. The thing that worked was the trellis underneath. Pulled out, generalized, it turns out to hold up software too.
Trellis Studio is the garden
The engine runs by itself. The Studio is where you tend the vines.
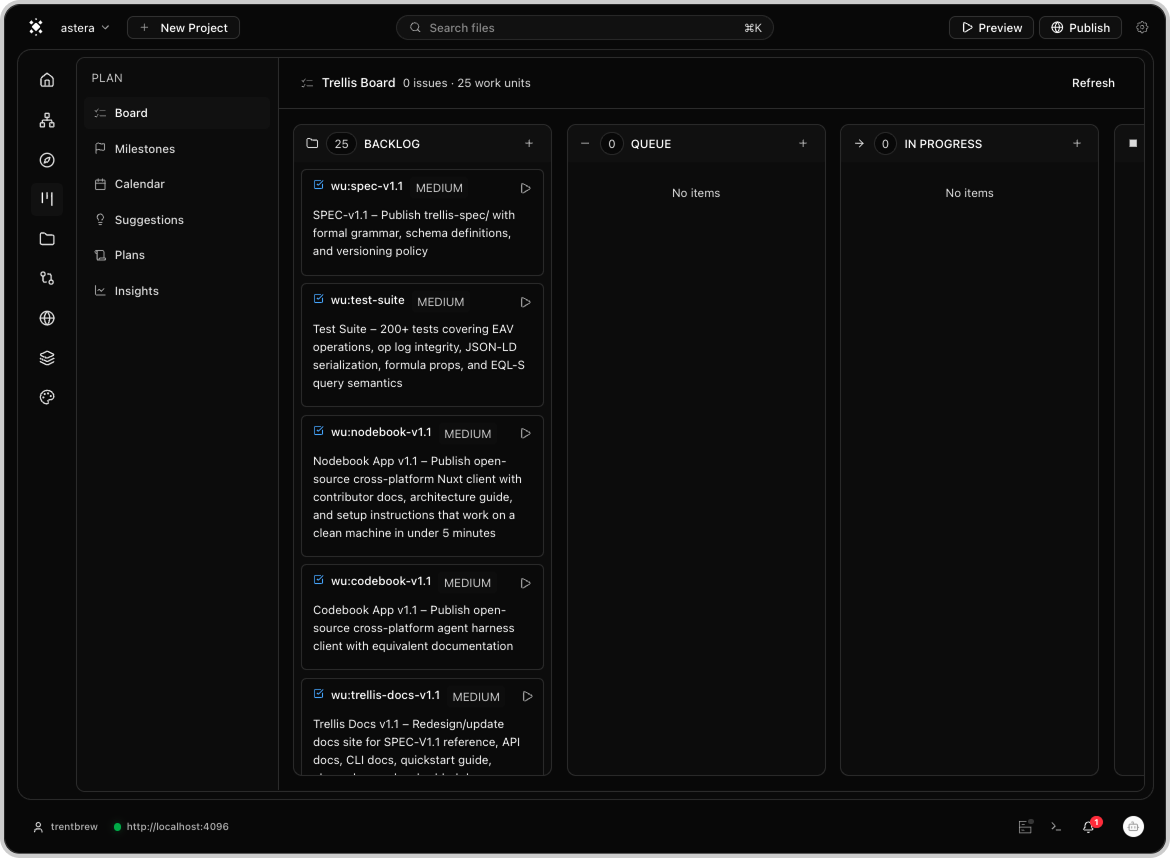
One screen, six tools that used to live in five different apps:
- Graph view. Entities, ops, and links as a living graph. Click to inspect anything
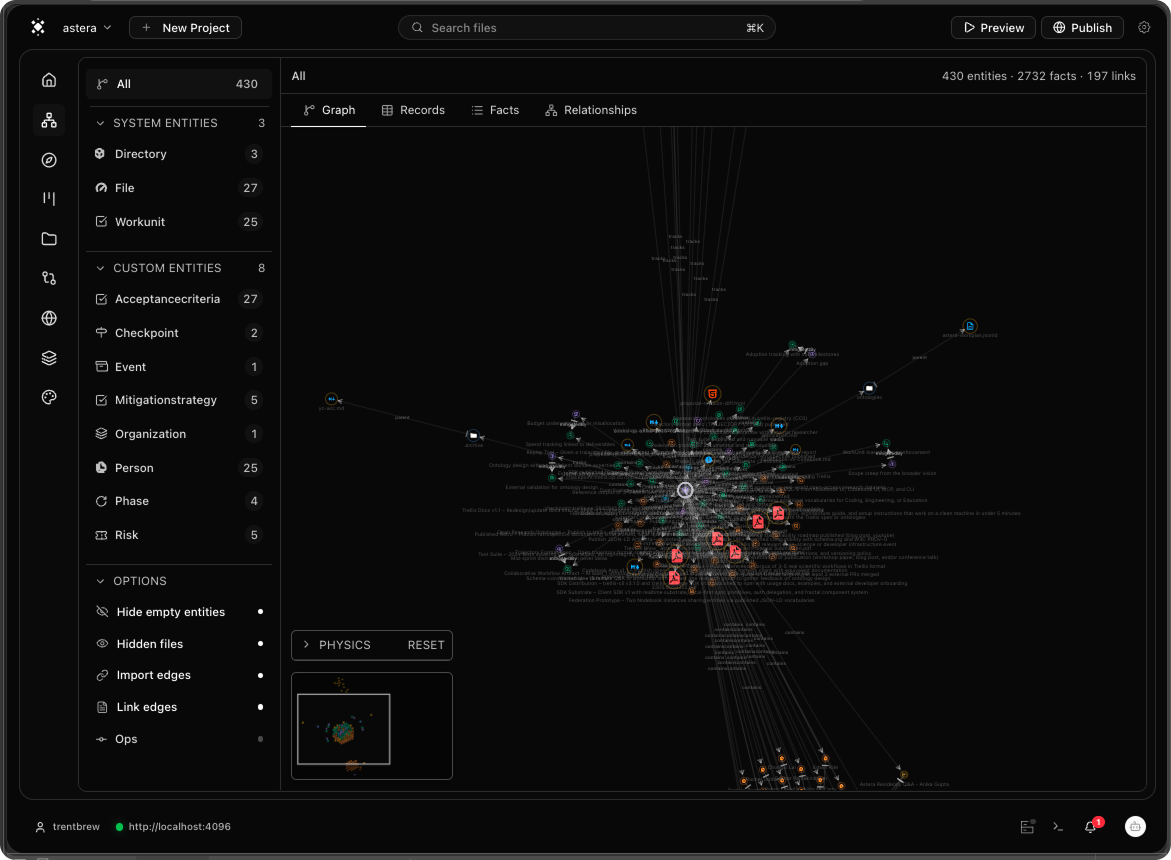
- Code Editor & Rich Text. Code entities in a tree, changes as causal steps.
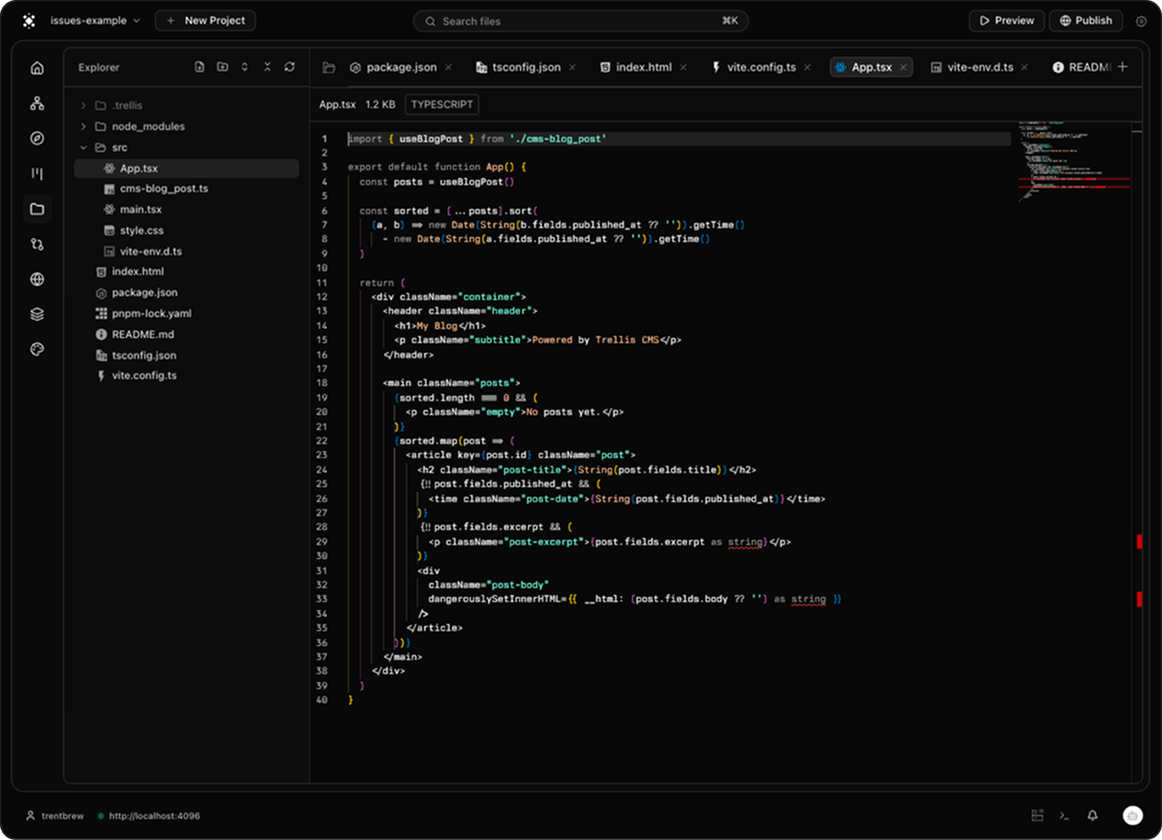
- History & Diffing. View history as a graph, with semantic diffing that understands structure, not lines.
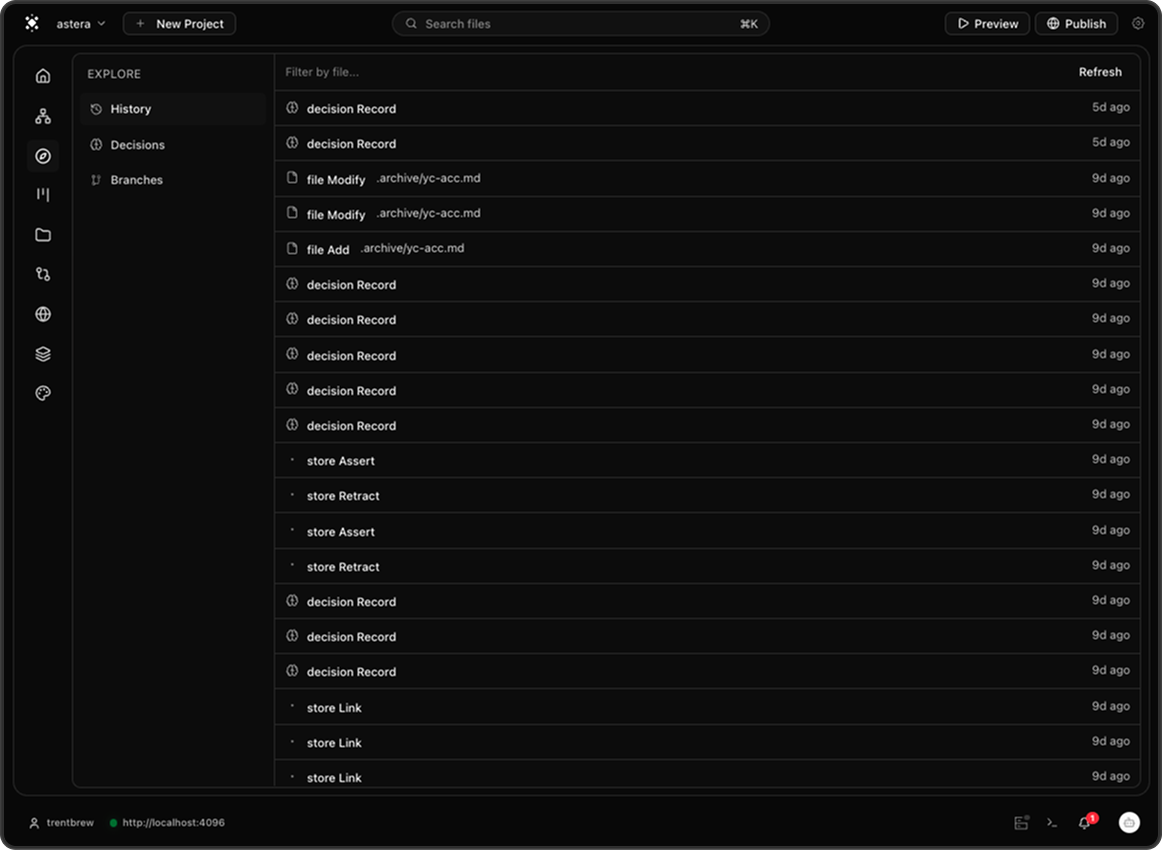
- Embedded agents. Agents run inside the workspace. Every tool call is an op, not a chat log.
- Decision traces. Capture the why behind every change. Search precedent across past runs.
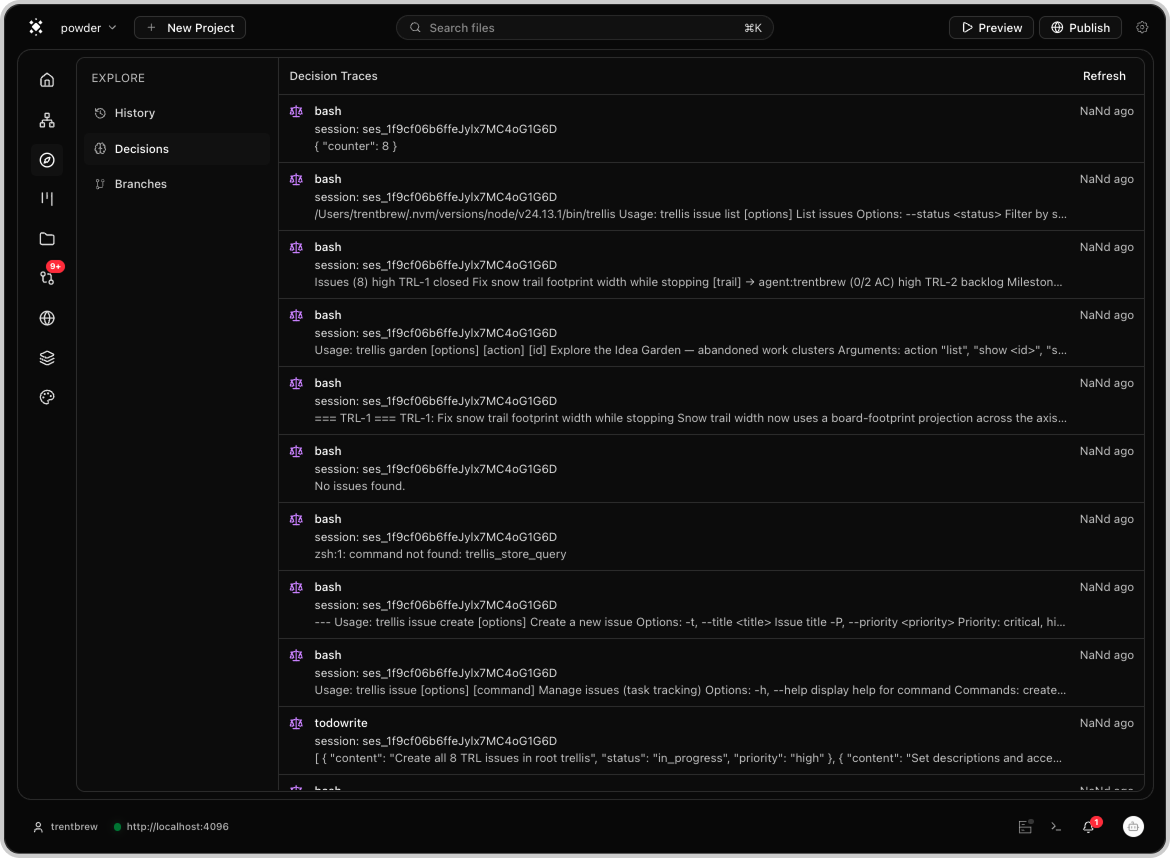
- Issues and milestones. Task tracking in the same graph as the code it ships with.
- Idea garden. Abandoned exploration stays searchable and revivable. Lost work isn’t lost; it’s just dormant.
- Semantic diffs. Code-aware patches that understand structure, not lines. Function renamed, not 12 lines changed.
Same graph, six surfaces.

To boot it:
npx trellis studio
No account. No cloud. No signup. Your project, your machine, your data.
How the trellis is built
Three parts.
1. The Graph Engine

Trellis is an EAV store (entities, attributes, values) plus a link index. Files, decisions, issues, and agent runs are all entities with stable IDs.

A fact:
{ e: "decision:DEC-42", a: "rationale", v: "SEV-1 precedent + finance exception" }
A link:
{ e1: "decision:DEC-42", a: "affects", e2: "file:src/auth/session.ts" }
Mutations produce immutable ops, content-addressed and causally chained. Reading the history of a file isn’t git log. It’s a graph query, and you can ask things git log can’t: what decisions affected this file, made by which agents, against what alternatives?
2. The Agent Harness
When an agent runs inside the Studio, every tool call emits an op. The chat is the user-facing surface; the op log is the durable record. Asking “why did the agent do that?” becomes a graph traversal, not an archaeological dig through scrollback.
This is the part that breaks the “RAG over chat history” pattern. The agent doesn’t have to remember its reasoning by searching its own logs. The reasoning is structured data in the same graph as the code it changed. Two composable steps from question to answer. No hallucination. No black box.
3. The Filesystem
The whole engine fits in a .trellis/ folder. SQLite for kernel state, JSON for entity collections, content-addressed blobs for ops. The filesystem is the source of truth; the graph is a materialized view, rebuilt on startup.
Backup is cp -r. Sync is optional. There’s a server you can run for collaboration, but it’s the second-best mode. The first-best mode is your machine.
What the trellis holds up
Here’s the part I keep coming back to.
The biggest unsolved problem in AI tooling right now is memory: not the model’s context window, but durable structure an agent can return to in a week and act on. Every team building AI products is hitting the same wall: their agents are brilliant in the moment and amnesiac five minutes later.
The current answers are all RAG over the agent’s own output. Store the chat log, embed it, retrieve relevant fragments. This works for vibes-level recall. It fails the moment you need anything causal: which decisions affected the auth subsystem last quarter and were later reversed? That’s a graph query, not a similarity search.
The way through is a structure that’s legible to both the agent and you. Agents need durable memory. Humans need to read it. If those are different systems, they desync. If they’re the same graph, the agent’s reasoning is in the same shape as the codebase it’s modifying. You can read either one without translation.
That’s what the trellis is holding up: one graph that holds the work of building software, structured enough that an agent can query it and a human can read it. One garden, two gardeners.
Try it out
npx trellis studio
Requires Node 18+ and git. Docs at trellis.computer.
Takeaways
- Code, decisions, and agent reasoning are vines. They don’t hold their own weight. Build them a structure or accept that most of them will rot.
- The substrate is the durable bet, not the surface. Filegraph’s canvas was the photogenic part. The substrate underneath was what was actually general.
- Local-first solves “agent memory” better than RAG-over-cloud. Embeddings work for similarity. They don’t work for causal claims.
- A graph you own beats a vector store you rent.
- Filegraph’s canvas can come back. As a Studio mode, on a substrate that’s done the unglamorous work first.
What’s next
- Canvas mode. The Filegraph payoff (spatial entity arrangement, projections, voice) but inside the Studio, over the same graph as your code.
- Hosted Trellis. For people who don’t want to install anything. Local-first stays the default; hosted is for when you need to share the garden.
- Broader semantic-patch coverage. Today TrellisVCS handles TypeScript, JavaScript, Python, and Markdown deeply. More languages, more operations.
- Multiplayer. Real-time collaboration on a shared graph, with op-level conflict resolution that’s actually correct because it’s working on structured data instead of lines.
For deeper architecture writeups (the EAV model, semantic patching, the decision-trace schema), separate technical posts are coming.
Docs: trellis.computer
Built at turtle.tech. Continuing the work of Filegraph.